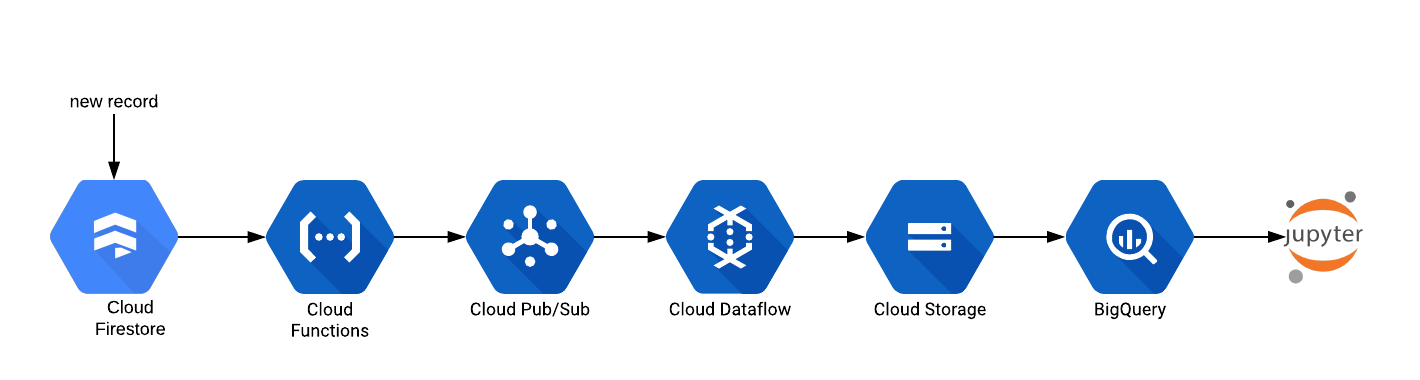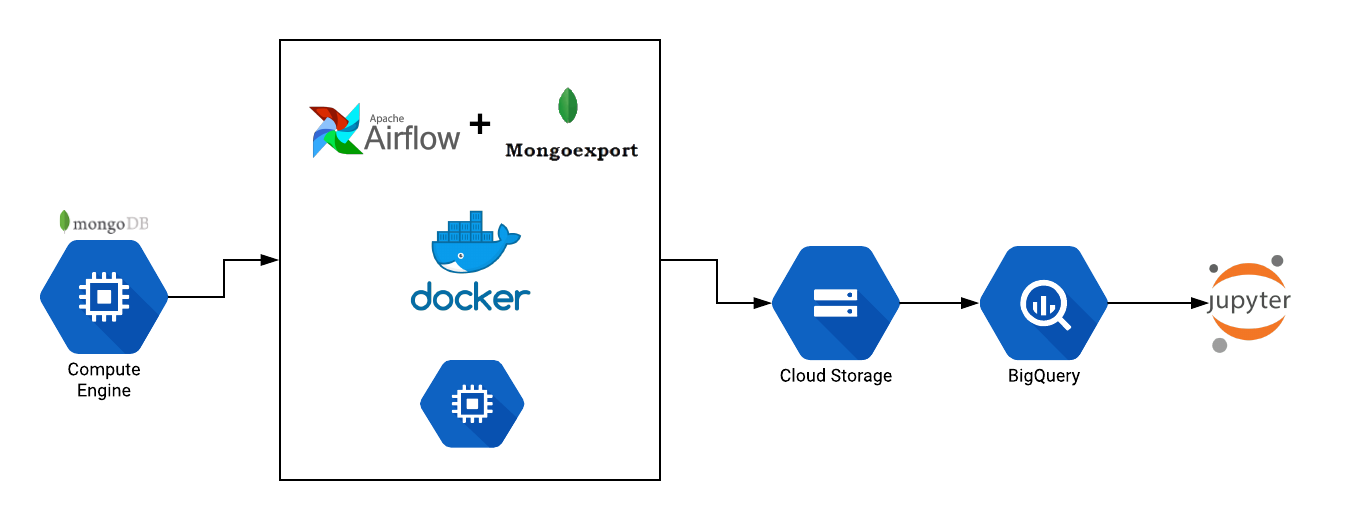
Creating an Automated Data Engineering Pipeline for Batch Data in Machine Learning
A common use case in Machine Learning life cycle is to have access to the latest training data so as to prevent model deterioration. A lot of times data scientists find it cumbersome to manually export data from data sources such as relational databases or NoSQL data stores or even distributed data. This necessitates automating... » read more