
Our focus in this post is to leverage Google Cloud Platform’s Big Data Services to build an end to end Data Engineering pipeline for streaming processes.
So what is Data Engineering?
Data Engineering is associated with data specifically around data delivery, storage and processing. The main goal is to provide a reliable infrastructure for data which includes operations such as collect, move, store and prepare data.
Most companies store their data in different formats across databases and as text files. This is where data engineers come in to picture, they build pipelines that transform this data into formats that data scientists could use.
Need for Data Engineering in Machine Learning:
Data engineers are responsible for:
- Develop machine learning models.
- Improve existing machine learning models.
- Research and implement best practices to enhance existing machine learning infrastructure.
- Developing, constructing, testing and maintaining architectures, such as databases and large-scale processing systems.
- Analyzing large and complex data sets to derive valuable insights.
This is the reference architecture used to build the end to end pipe data pipeline :
The Google Cloud Services used in above streaming process are:
- Cloud Firestore: Lets us store data in cloud so that we could sync it across all other devices and also share among multiple users. It is a NoSQL query document data which lets us store, query and sync.
- Cloud Function: A lightweight compute solution for developers to create single-purpose, stand-alone functions that respond to cloud events without the need to manage a server or runtime environment.
- Cloud Pub/Sub: A fully-managed real-time messaging service that allows you to send and receive messages across independent applications.
- Cloud Dataflow: A cloud-based data processing service for both batch and real-time data streaming applications. It enables developers to set up data processing pipelines for integrating, preparing and analyzing large data sets.
- Cloud Storage: A data storage service in which data is maintained, managed, backed up remotely and made available to users over a network.
- BigQuery: It was designed for analyzing data on the order of billions of rows, using a SQL-like syntax. It runs on the Google Cloud Storage infrastructure and could be accessed with a REST-oriented application programming interface (API).
- Jupyter notebook: An open source web application that you could use to create and share documents that contain live code, equations, visualizations, and text.
Create data engineering pipeline via Firestore Streaming
Step1: Add a new record in a collection (think of it as a table), say pubsub-event in firestore.


Step2: It triggers the cloud function named pubsub_event.

Document Path: pubsub-event/{eventId} listens for changes to all pubsub-event documents.
Below is the Cloud Function written in node js which triggers whenever there is a change in our source Firestore collection and publishes the data to Pub/Sub
const PubSub = require('@google-cloud/pubsub');
const pubsubClient = new PubSub();
const functions = require('firebase-functions');
exports.helloFirestore = functions.firestore
.document("pubsub-event/{eventId}")
.onCreate((snap, context) => {
const event = snap.data();
const payload_data = {};
for (let key of Object.keys(event)) {
payload_data[key] = event[key];
}
console.log(JSON.stringify(payload_data))
// The name for the new topic
const topicName = 'pubsub-gcs';
const dataBuffer = Buffer.from(JSON.stringify(payload_data));
// Creates the new topic
return pubsubClient
.topic(topicName)
.publisher()
.publish(dataBuffer)
.then(messageId => {
console.log(`Message ${messageId} published.`);
return messageId;
})
.catch(err => {
console.error('ERROR:', err);
});
});Below is the dependencies of the Cloud Function.
{
"name": "functions",
"description": "Cloud Functions for Firebase",
"scripts": {
"serve": "firebase serve --only functions",
"shell": "firebase functions:shell",
"start": "npm run shell",
"deploy": "firebase deploy --only functions",
"logs": "firebase functions:log"
},
"engines": {
"node": "8"
},
"dependencies": {
"@google-cloud/pubsub": "^0.18.0",
"firebase-admin": "~7.0.0",
"firebase-functions": "^2.3.1"
},
"devDependencies": {
"firebase-functions-test": "^0.1.6"
},
"private": true
}Step3: Cloud Function pubsub_event publishes data to Pub/Sub topic projects/ProjectName/topics/pubsub-gcs


Step4: As shown above, create an export job : ps-to-text-pubsub-gcs (implemented via Dataflow). This job reads data every 5 minutes (configurable to other values as well) from Pub/Sub topic pubsub-gcs and dumps this into the destination bucket on GCS.


Click on run the job.

Step6: Now, we have data in CloudStorage. We shall use BigQuery to perform all the data manipulation operations. But first we need to create dataset in BigQuery to query data from GCS into Bigquery.
Go to BigQuery and create dataset. So that we create our table to access that data.

The dataset shall be created. By clicking on the dataset you shall see an option to CREATE TABLE.

Click on CREATE TABLE then we shall get the data from CloudStorage. While setting up the required inputs as indicated below, please make sure that you select “Table type” as External Table. This ensures that BigQuery is able to automatically load new data as it comes into GCS.
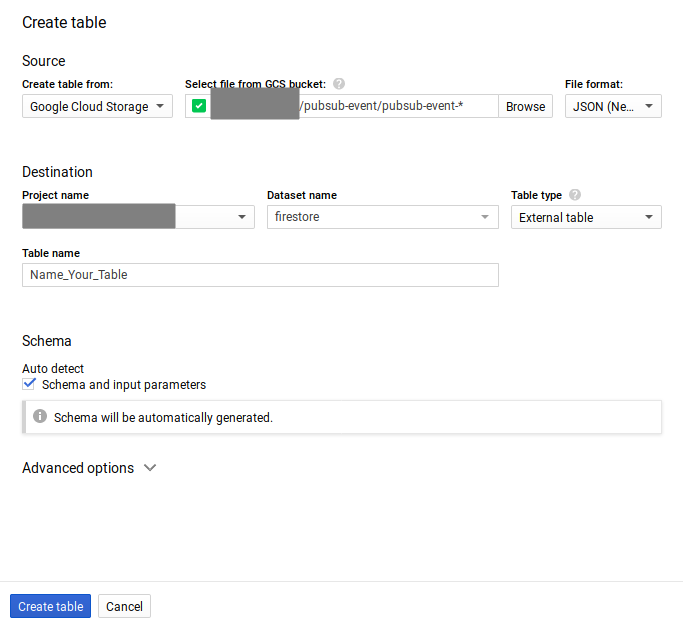
To create table in BigQuery from CloudStorage. Click on the browse button and configure file path.

Files that are having pubsub-event-* as prefix. This prefix is very important as it makes sure that all subsequent data dumps into GCS destination folder are also picked automatically by BigQuery. Select the file format to be JSON. Check the auto-detect schema box. Then click create table.
Quick Tip: For reading nested json files in BigQuery, please go through this resource. Now the data which is present in CloudStorage is also available in BigQuery and you could run sql commands to manipulate the data.

Click on table you have created, accounts is my table name and click on query table to make SQL operations and you could see your results in the preview tab at the bottom.
Step7: Now, we are on to the last step to access this BigQuery data in Jupyter Notebooks and use that as the source data to train and build our ML models.
Search for notebook in GCP console.


You shall see something like this

Click on OPEN JUPYTERLAB then it will redirect you to notebook.
from google.cloud import bigquery
client = bigquery.Client()
sql = """
SELECT * FROM
`<project-name>.<dataset-name>.<table-name>`
"""
df = client.query(sql).to_dataframe()
df.head(10)So in this way, we have built a data pipeline that continuously dumps data from Firestore into GCS every 5 minutes, which is then readily available in Jupyter Notebook via BigQuery for any downstream analytics and ML model building.
Look forward to your comments.
This story is co-authored by Santosh Kumar and PV Subbareddy. Santosh is a Software Engineer specializing on Cloud Services and DevOps. Subbareddy is a Big Data Engineer specializing on AWS Big Data Services and Apache Spark Ecosystem.
Comments
BigQuery: It was designed for analyzing data on the order of billions of rows, using a SQL-like syntax. It runs on the Google Cloud Storage infrastructure and could be accessed with a REST-oriented application programming interface (API).
<>