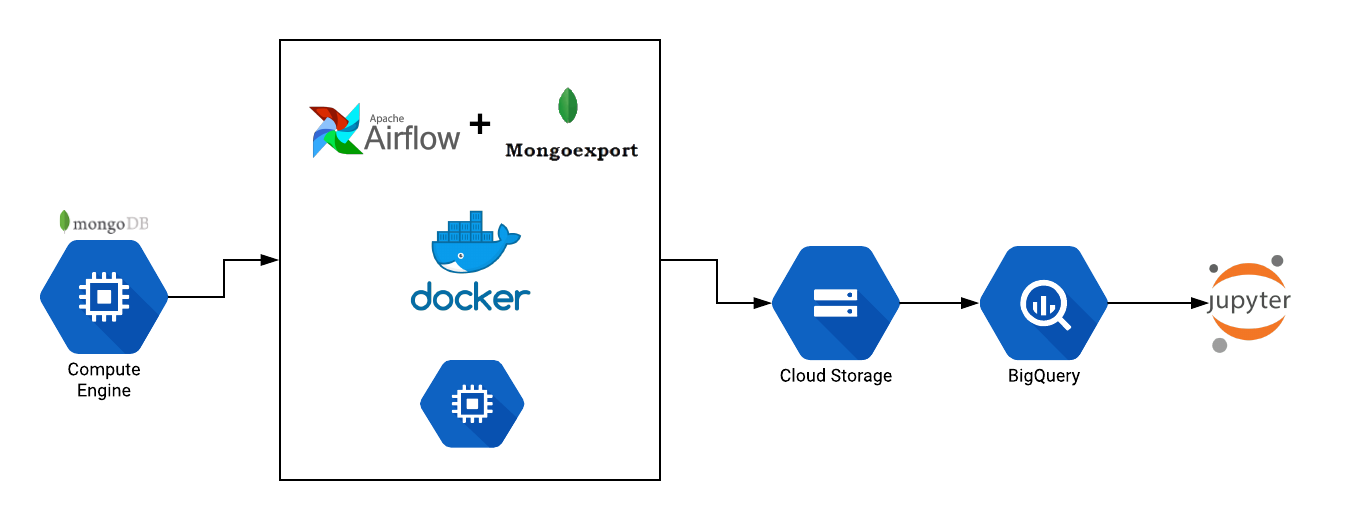
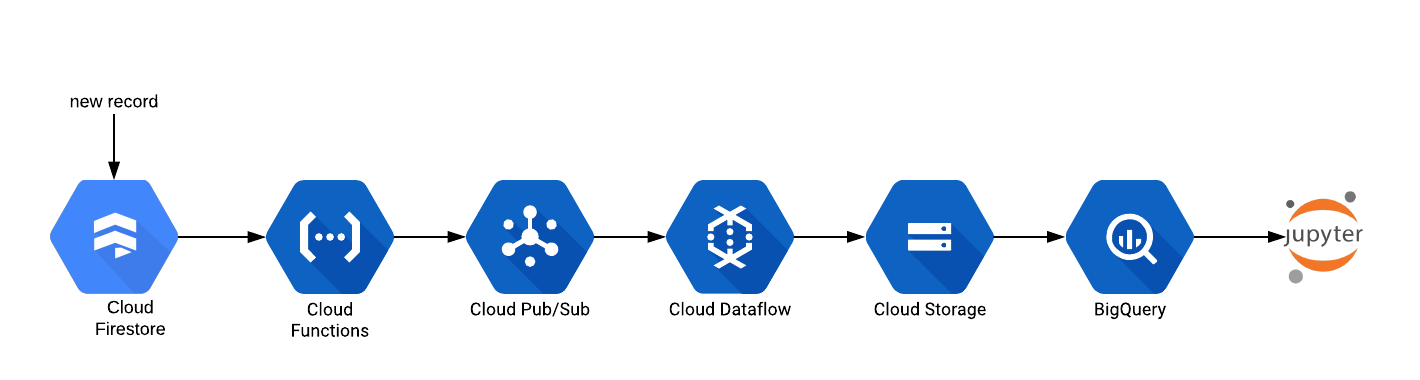
Machine Learning Operations (MLOps) Pipeline using Google Cloud Composer
In an earlier post, we had described the need for automating the Data Engineering pipeline for Machine Learning based systems. Today, we will expand the scope to setup a fully automated MLOps pipeline using Google Cloud Composer. Cloud Composer Cloud Composer is official defined as a fully managed workflow orchestration service that empowers you to... » read more