
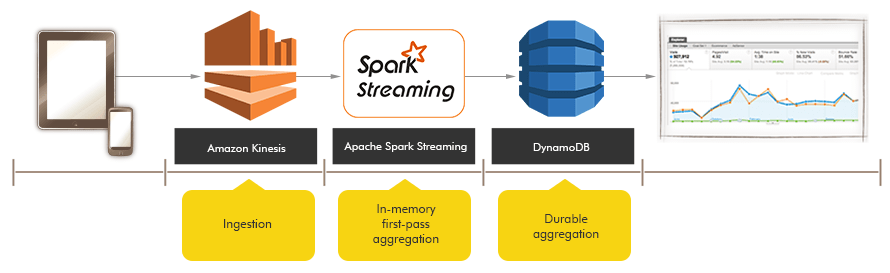
Solution Overview : In this blog, we are going to build a real time anomaly detection solution using Spark Streaming. Kinesis Data Streams would act as the input streaming source and the anomalous records would be written as Data Streams in DynamoDB.
Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events.
Data Streams
The unit of data stored by Kinesis Data Streams is a data record. A data stream represents a group of data records.
For deep dive into Kinesis Data Streams, please go through these official docs.
Kinesis Data Streams Producers
A producer puts data records into Amazon Kinesis Data Streams. For example, a web server sending log data to a Kinesis Data Stream is a producer.
For more details about Kinesis Data Streams Producers, please go through these official docs.
Kinesis Data Streams Consumers
A consumer, known as an Amazon Kinesis Data Streams application, is an application that you build to read and process data records from Kinesis Data Streams.
For more details about Kinesis Data Streams Consumers, please go through these official docs.
Creating a Kinesis Data Stream
Step1. Go to Amazon Kinesis console -> click on Create Data Stream
Step2. Give Kinesis Stream Name and Number of shards as per volume of the incoming data. In this case, Kinesis stream name as kinesis-stream and number of shards are 1.
Shards in Kinesis Data Streams
A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity.
For more about shards, please go through these official docs.
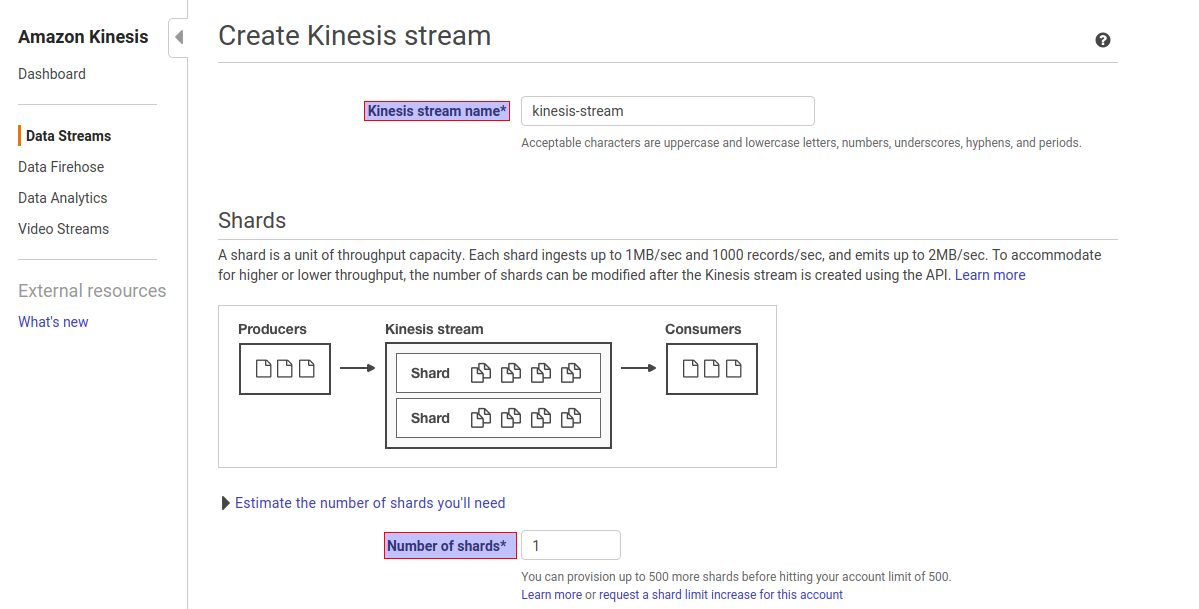
Step3. Click on Create Kinesis Stream
Kinesis Data Streams can be connected with Kinesis Data Firehoseto write the streamsinto S3.
Configure Kinesis Data Streams with Kinesis Data Producers
The Amazon Kinesis Data Generator (KDG) makes it easy to send data to Kinesis Streams or Kinesis Firehose.
While following this link, choose to Create a Cognito User with Cloud Formation.
After selecting the above option, we will navigate to the Cloud Formation console:
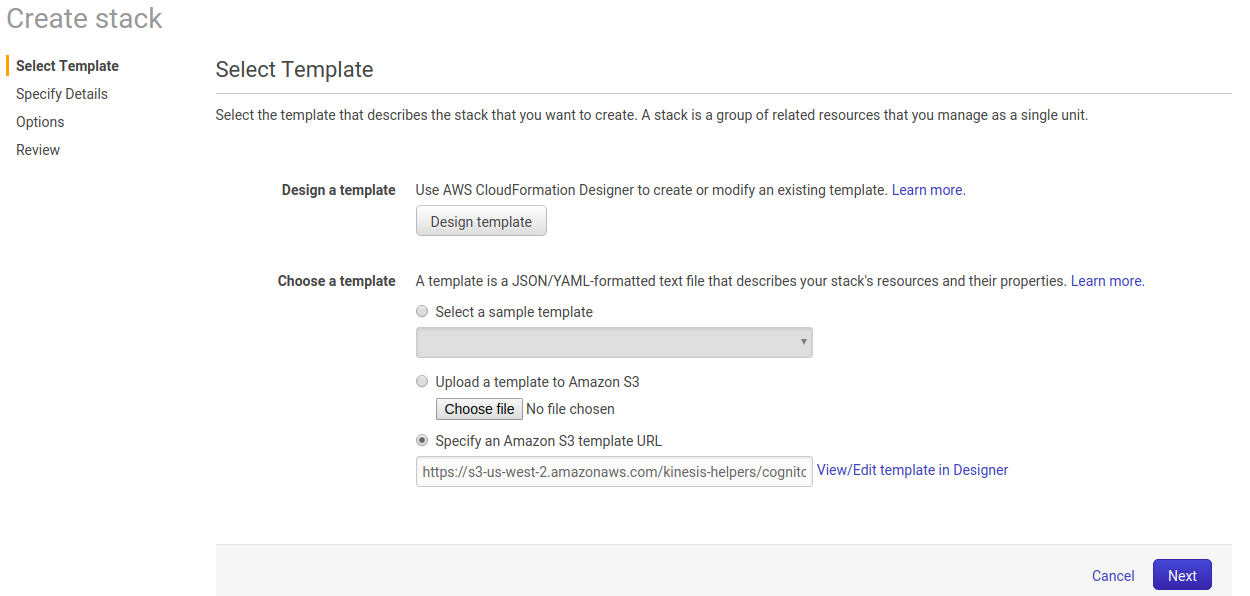
Click on Next and provide Username and Password for Cognito User for Kinesis Data Generator.
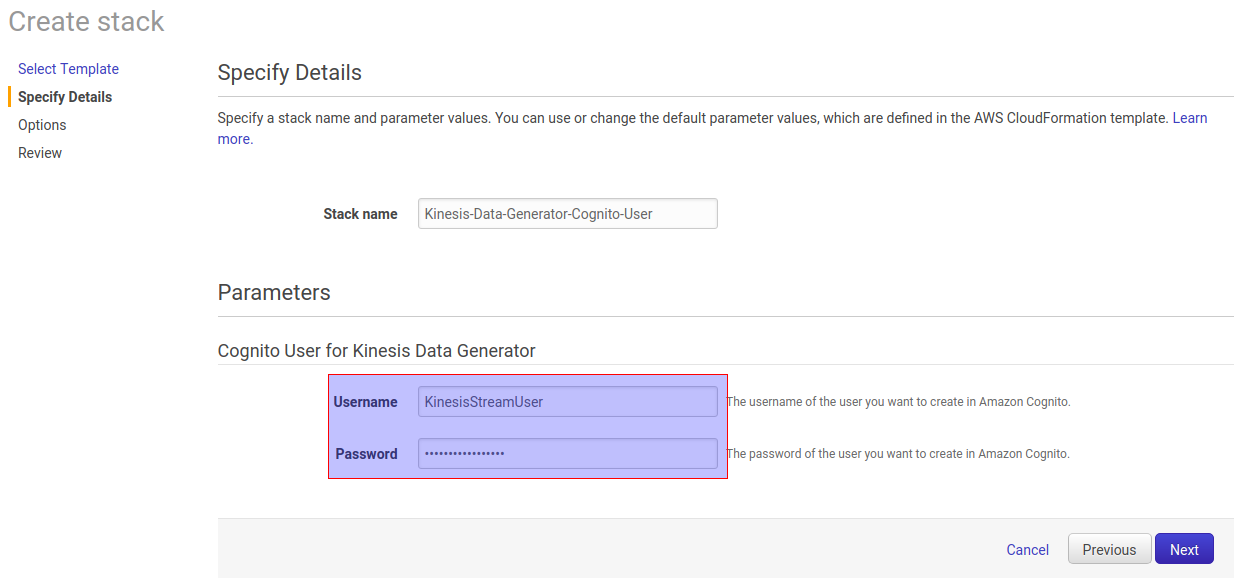
Click on Next and Create Stack.
CloudFormation Stack is created.
Click on Outputs tab and open the link
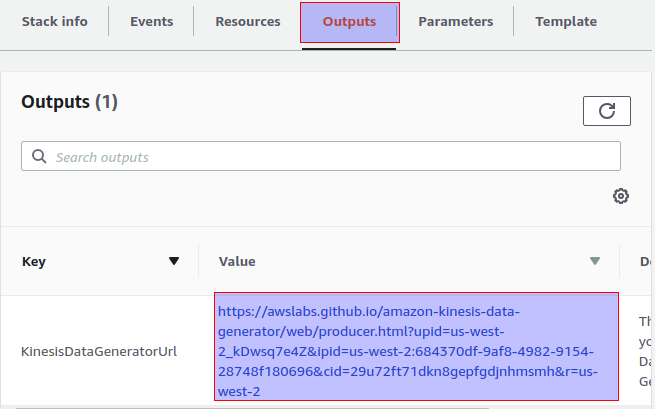
After opening the link, enter the usernameand password of Cognito user.
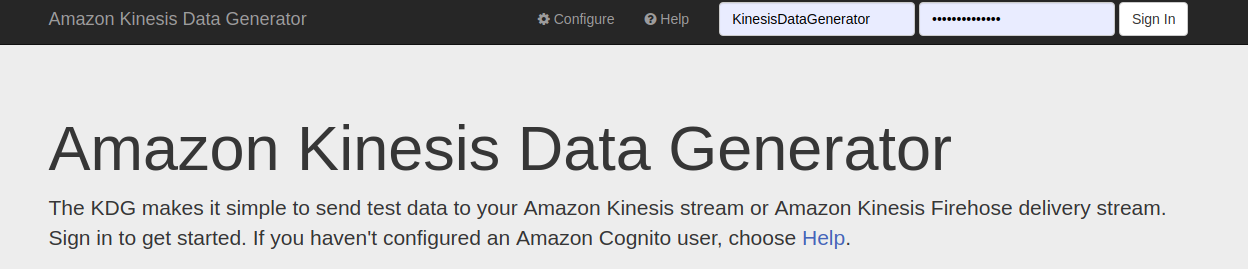
After Sign In is completed, select the Region, Stream and configure the number of records per second. Choose record template as your requirement.
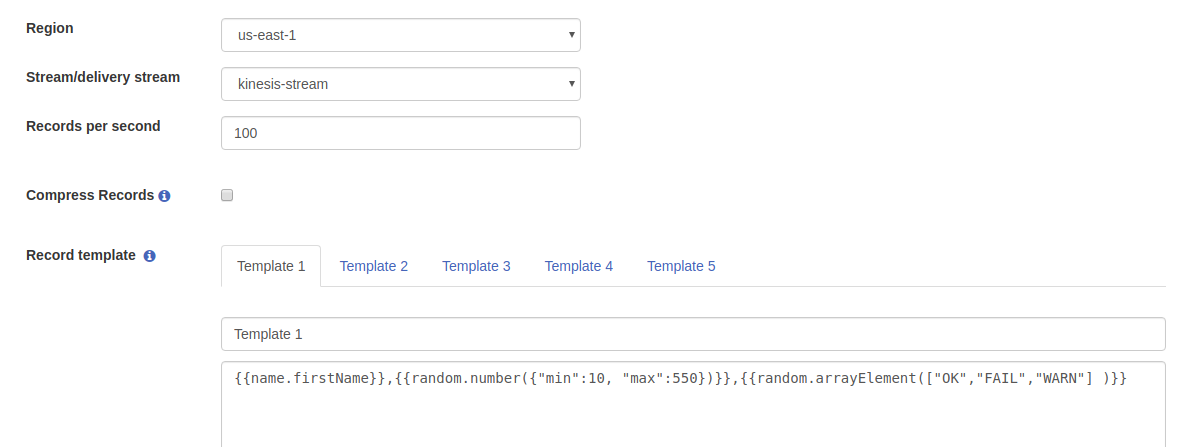
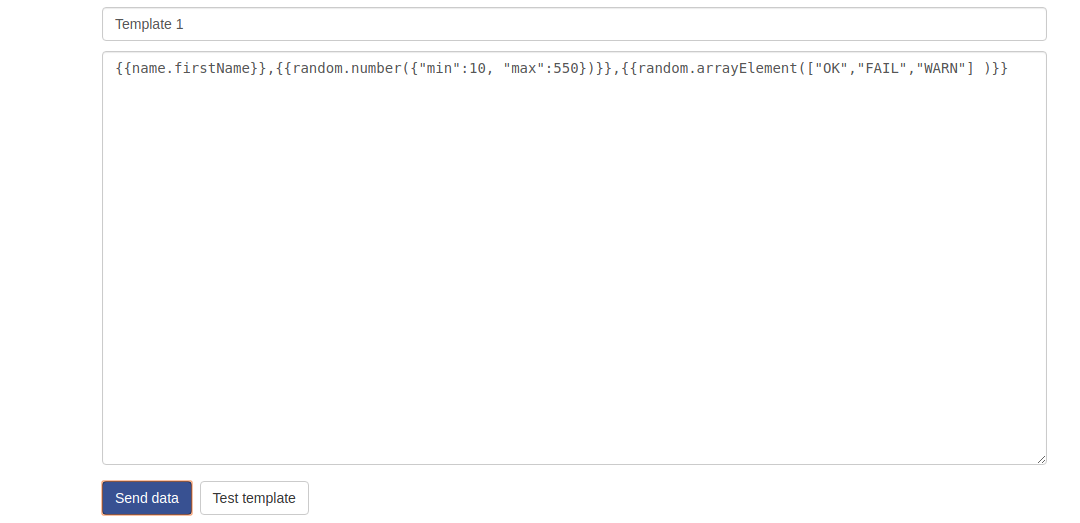
In this case, the template data format is
{{name.firstName}},{{random.number({“min”:10, “max”:550})}},{{random.arrayElement([“OK”,”FAIL”,”WARN”] )}}
The template data looks like the following
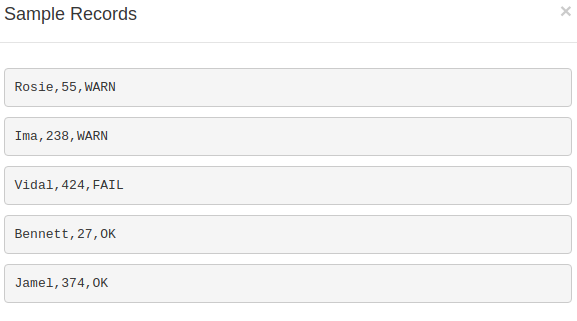
You can send different types of dummy data to Kinesis Data Streams.
Kinesis Data Streams with Kinesis Data Producers are ready. Now we shall build a Spark Streaming application which consumes data streams from Kinesis Data Streams and dumps the output streams into DynamoDB.
Create DynamoDB Tables To Store Data Frame
Go to Amazon DynamoDB console -> Choose Create Table and name the table, in this case, data_dump
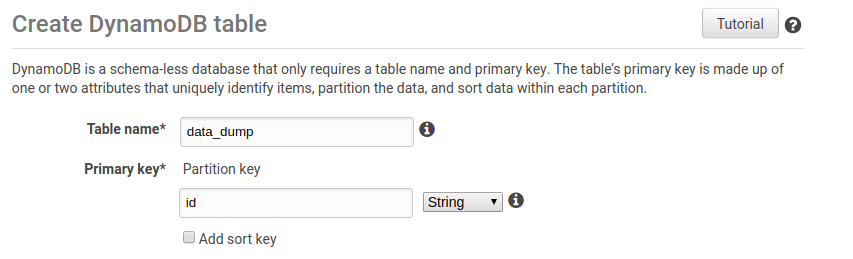
In the same way, create another table named anomaly_data. Make sure Kinesis Data streams and DynamoDb tables are in the same region.
Spark Streaming with Kinesis Data Streams
Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window.
For deep dive into Spark Streams, please go through docs.
In this case, the Scala programming language is used. Scala version is 2.11.12. Please install scala, sbt and spark.
Create a folder structure like the following
Kinesis-spark-streams-dynamo
| -- src/main/scala/packagename/object
| -- build.sbt
| -- project/assembly.sbt
In this case, the structure looks like the following

After creating the folder structure,
Please replace build.sbt file with the following code. The following code will add the required dependencies like spark, spark kinesis assembly, spark streaming and many more.
name := "kinesis-spark-streams-dynamo"
version := "0.1"
scalaVersion := "2.11.12"
libraryDependencies += "com.audienceproject" %% "spark-dynamodb" % "0.4.1"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.3"
libraryDependencies += "com.google.guava" % "guava" % "14.0.1"
libraryDependencies += "com.amazonaws" % "aws-java-sdk-dynamodb" % "1.11.466"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kinesis-asl" % "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.3"
assemblyMergeStrategy in assembly := {
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x => MergeStrategy.first
}
Please replace assembly.sbt file with the following code. This will add the assembly plugin which can be used for creating the jar.
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.9")
Please replace kinesis-spark-streams-dynamo file with the following code.
package com.wisdatum.kinesisspark
import com.amazonaws.auth.DefaultAWSCredentialsProviderChain
import org.apache.spark._
import org.apache.spark.streaming._
import com.amazonaws.services.kinesis.AmazonKinesis
import scala.collection.JavaConverters._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kinesis.KinesisInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.DStream
import com.amazonaws.regions.RegionUtils
import com.amazonaws.services.kinesis.AmazonKinesisClient
import org.apache.log4j.{Level, Logger}
import com.audienceproject.spark.dynamodb.implicits._
object KinesisSparkStreamsDynamo {
def getRegionNameByEndpoint(endpoint: String): String = {
val uri = new java.net.URI(endpoint)
RegionUtils.getRegionsForService(AmazonKinesis.ENDPOINT_PREFIX)
.asScala
.find(_.getAvailableEndpoints.asScala.toSeq.contains(uri.getHost))
.map(_.getName)
.getOrElse(
throw new IllegalArgumentException(s"Could not resolve region for endpoint: $endpoint"))
}
def main(args: Array[String]) {
val rootLogger = Logger.getRootLogger()
rootLogger.setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("KinesisSparkExample").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(1))
println("Launching")
val Array(appName, streamName, endpointUrl, dynamoDbTableName) = args
println(streamName)
val credentials = new DefaultAWSCredentialsProviderChain().getCredentials()
require(credentials != null,
"No AWS credentials found. Please specify credentials using one of the methods specified " +
"in http://docs.aws.amazon.com/AWSSdkDocsJava/latest/DeveloperGuide/credentials.html")
val kinesisClient = new AmazonKinesisClient(credentials)
kinesisClient.setEndpoint(endpointUrl)
val numShards = kinesisClient.describeStream(streamName).getStreamDescription().getShards().size
println("numShards are " + numShards)
val numStreams = numShards
val batchInterval = Milliseconds(100)
val kinesisCheckpointInterval = batchInterval
val regionName = getRegionNameByEndpoint(endpointUrl)
val anomalyDynamoTable = "data_anomaly"
println("regionName is " + regionName)
val kinesisStreams = (0 until numStreams).map { i =>
KinesisInputDStream.builder
.streamingContext(ssc)
.streamName(streamName)
.endpointUrl(endpointUrl)
.regionName(regionName)
.initialPositionInStream(InitialPositionInStream.LATEST)
.checkpointAppName(appName)
.checkpointInterval(kinesisCheckpointInterval)
.storageLevel(StorageLevel.MEMORY_AND_DISK_2)
.build()
}
val unionStreams = ssc.union(kinesisStreams)
val inputStreamData = unionStreams.map { byteArray =>
val Array(sensorId, temp, status) = new String(byteArray).split(",")
StreamData(sensorId, temp.toInt, status)
}
val inputStream: DStream[StreamData] = inputStreamData
inputStream.window(Seconds(20)).foreachRDD { rdd =>
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val inputStreamDataDF = rdd.toDF()
inputStreamDataDF.createOrReplaceTempView("hot_sensors")
val dataDumpDF = spark.sql("SELECT * FROM hot_sensors ORDER BY currentTemp DESC")
dataDumpDF.show(2)
dataDumpDF.write.dynamodb(dynamoDbTableName)
val anomalyDf = spark.sql("SELECT * FROM hot_sensors WHERE currentTemp > 100 ORDER BY currentTemp DESC")
anomalyDf.write.dynamodb(anomalyDynamoTable)
}
// To make sure data is not deleted by the time we query it interactively
ssc.remember(Minutes(1))
ssc.start()
ssc.awaitTermination()
}
}
case class StreamData(id: String, currentTemp: Int, status: String)
appName: The application name that will be used to checkpoint the Kinesis sequence numbers in the DynamoDB table.
- The application name must be unique for a given account and region.
- If the table exists but has incorrect checkpoint information (for a different stream, or old expired sequenced numbers), then there may be temporary errors.
kinesisCheckpointInterval:
The interval (e.g., Duration(2000) = 2 seconds) at which the Kinesis Client Library saves its position in the stream. For starters, set it to the same as the batch interval of the streaming application.
endpointURL:
Valid Kinesis endpoints URL can be found here.
For more details about building KinesisInputDStream, please go through the documentation.
Configure AWS Credentials using environment variables or using aws configure command.
Make sure all the resources are under the same account and region. Region of CloudFormation Stack that was created is in us-west-2 even though all the resources are in another region, this would not affect the process.
Building Executable Jar
- Open Terminal -> Go to project root directory, in this case
kinesis-spark-streams-dynamo

- Run sbt assembly
The jar has been packaged into project root directory/target/scala-2.11/XXXX.jar. Name of the jar is the name that provided in build.sbt file.
Run the Jar using spark-submit
- Open Terminal -> Go to Spark bin directory

- Run the following command, and it looks like
./bin/spark-submit ~/Desktop/kinesis-spark-streams-dynamo/target/scala-2.11/kinesis-spark-streams-dynamo-assembly-0.1.jar appName streamName endpointUrl dynamoDbTable
To know more about how to submit applications using spark-submit, please review this.
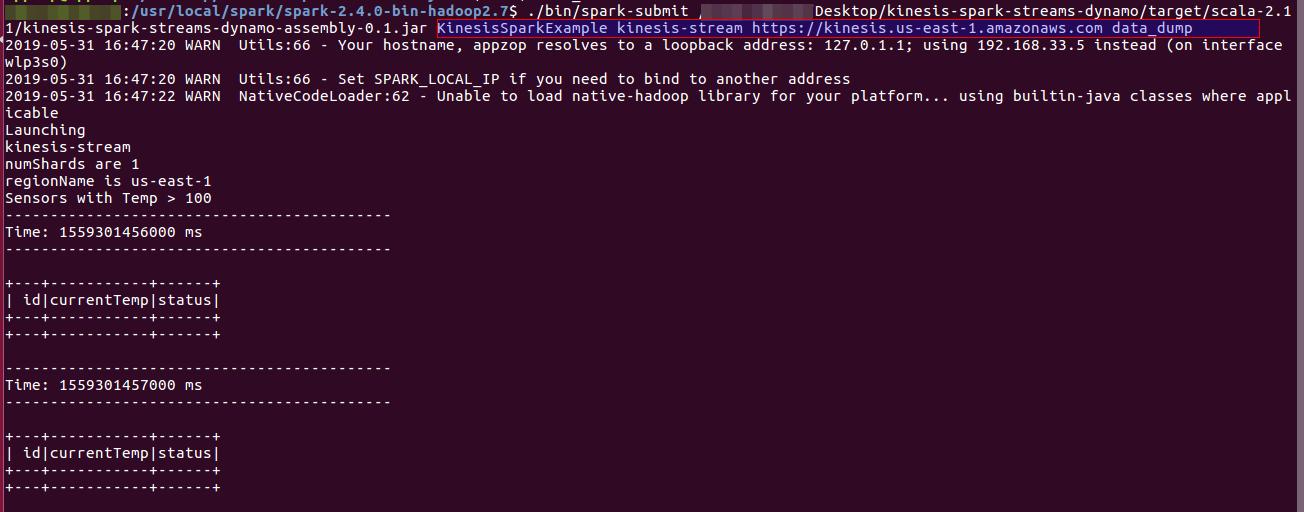
Arguments that are passed are highlighted in the above highlighted blue box. Place the arguments as needed.
Read Kinesis Data Streams in Spark Streams
- Go to Amazon Kinesis Data Generator-> Sign In using Cognito user
- Click on Send Data, it starts sending data to Kinesis Data Streams
Data would be sent to Kinesis Data Stream, in this case, kinesis-stream, it looks like this.
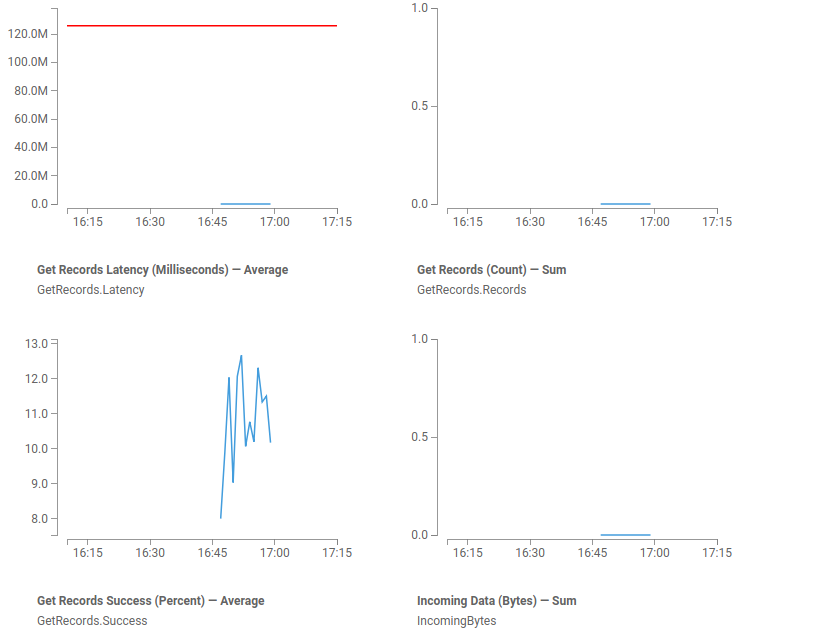
Monitoring Kinesis Data Streams
Go to Amazon Kinesis Console -> Choose Data streams -> Select created Data Stream -> click on Monitoring
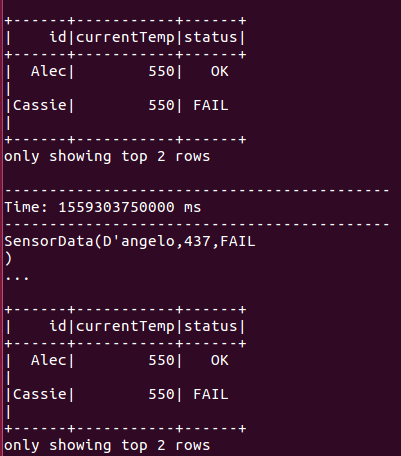
The terminal looks like the following when it starts receiving the data from Kinesis Data Streams
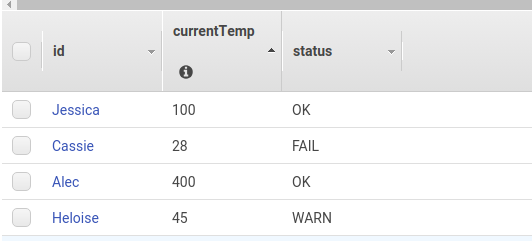
The data_dump table has the whole data that is coming from Kinesis Data Streams. And the data in the data_dump table looks like
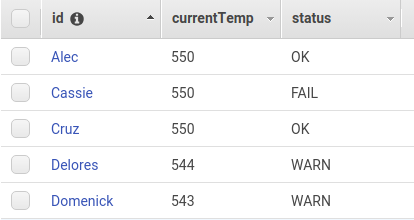
The data_anomaly table has data where currentTemp is greater than 100. Here the anomaly is temperature greater than 100. And the data in the data_anomaly table looks like
I hope this article was helpful in setting up Kinesis Data Streams that are consumed and processed using Spark Streaming and stored in DynamoDB.
This story is authored by P V Subbareddy. He is a Big Data Engineer specializing on AWS Big Data Services and Apache Spark Ecosystem.
Comments