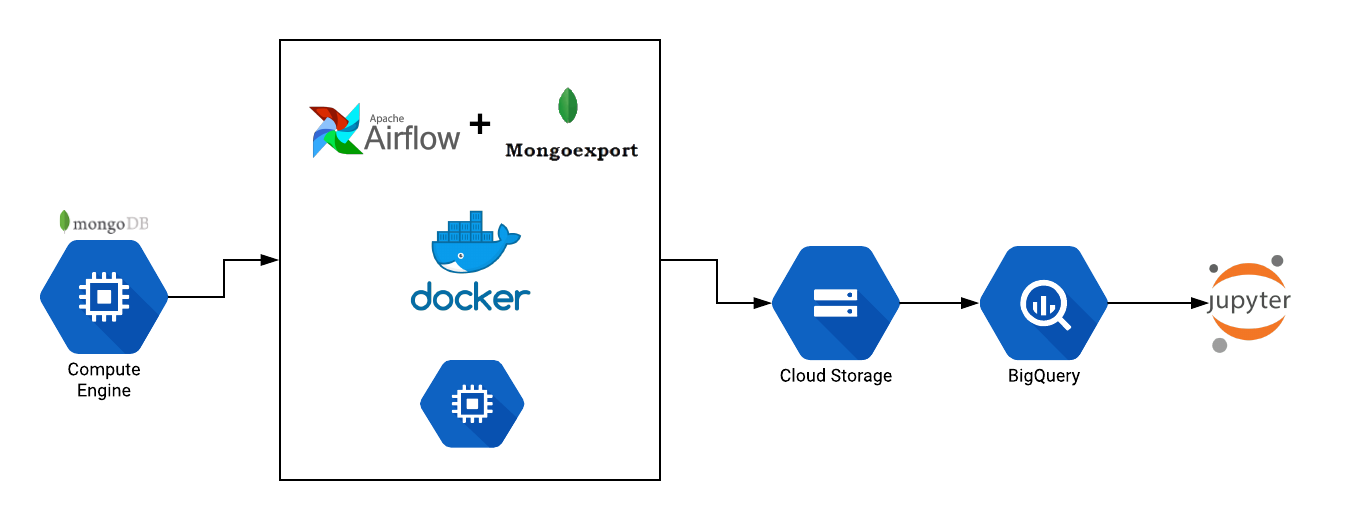
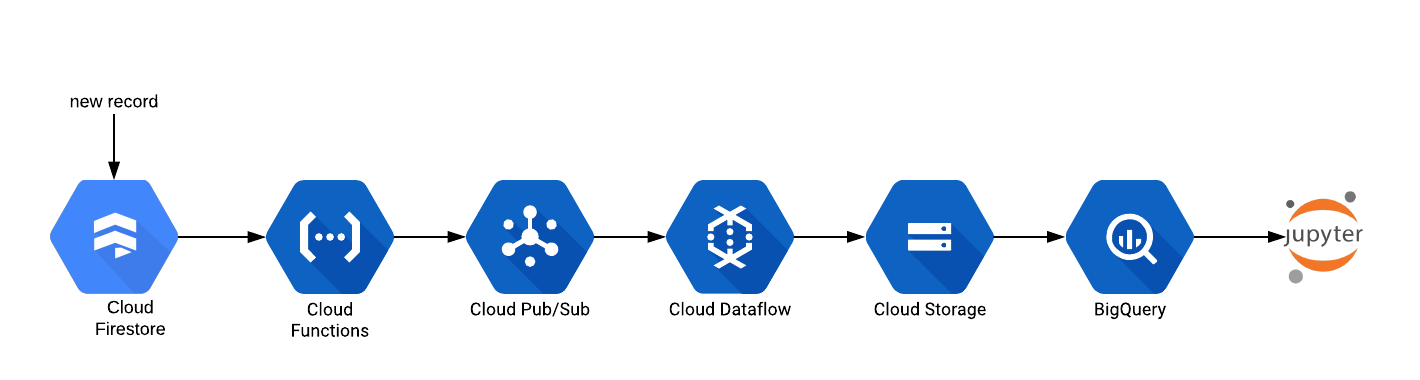
Create Voice Driven HealthCare Chatbot in React Native Using Google DialogFlow
In our earlier blog post, we had built a Healthcare Chatbot, in React Native using Dialogflow API. This blog is an extension of the chatbot we built earlier. We shall learn how to add support for voice-based user interaction to that chatbot. Assuming you had followed our earlier blog and created the chatbot we will... » read more