
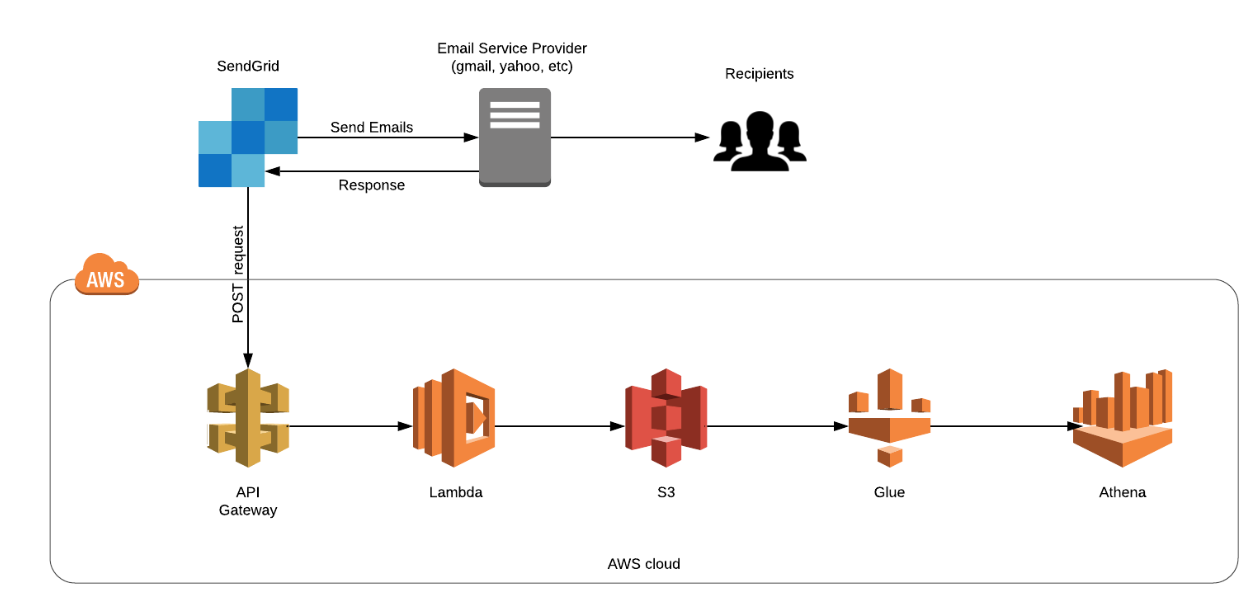

In this post, we will run though a case study to setup an email deliverability analytics pipeline using SendGrid and AWS Big Data Services such as S3, Glue and Athena. To start off, when we send mails from SendGrid to recipients. we get responses (multiple response types are possible such as processed, delivered, blocked, deferred etc) from Email Service Providers such as gmail, yahoo etc. We could use this response data to improve our Email Deliverability by analyzing this email response data. This is achieved by logging these responses (via API Gateway and Lambda function) into Amazon S3 and then analyzing them using Athena. The chain of events is put in place by using a web hook that triggers a post request to AWS API Gateway on an event notification (response) from SendGrid. The API Gateway is further configured to trigger a Lambda Function which writes the email response data into S3. We then use Glue crawler to update the metadata in data catalogue, thereby making it available for Athena to perform SQL based analysis.
Without further ado, let’s set the ball rolling. Go to SendGrid and select Settings>Mail_Settings. Click on Event Notifications

We are gonna enable it by giving an Endpoint and select the Events for which you want to get a response.

The above endpoint points to the AWS API Gateway (shown below) which is a POST request and it triggers the Lambda function as you can see.

Now our Lambda function stores the event payload data in S3 Bucket
Lambda code:
const AWS = require('aws-sdk')
var s3Bucket = new AWS.S3( { params: {Bucket: "Your-Bucket"} } );
exports.handler = (event, context, callback) => {
console.log(event); // the response data
let x = "";
event.map((item)=>{
x = x + JSON.stringify(item) + "\n"
})
let uuid = create_UUID();
var filePath = "receivelogs/"+uuid;
console.log(filePath);
var data = {
Key: filePath,
Body: x
};
s3Bucket.putObject(data, function(err, data){
if (err) {
console.log('Error uploading data: ', data);
callback(err, null);
} else {
console.log('Successfully uploaded the response');
callback(null, data);
}
});
};
// this function will generate Unique User ID. Used as FileName
function create_UUID(){
var dt = new Date().getTime();
var uuid = 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = (dt + Math.random()*16)%16 | 0;
dt = Math.floor(dt/16);
return (c=='x' ? r :(r&0x3|0x8)).toString(16);
});
return uuid;
}When you send mail, the response is triggered from SendGrid via POST request to API Gateway and then the response gets stored in S3 via Lambda function.

AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. We use a crawler to populate the AWS Glue Data Catalog with tables. Below is the step-by-step process to setup the Glue crawler to read an S3 based data source and make it available as a database table for AWS Athena based analytics.



In the step above, you may need to create a new IAM role that provides access to the underlying S3 data.



So in the steps above, we have concluded the setup for the crawler to fetch the underlying data on S3.


When you run this crawler on the S3 based data source, it updates the metadata of objects in that path in Glue data catalogue. Now, Athena can query ( SQL operations) those objects in S3 using metadata available in data catalogue. A lot of business executives aren’t comfortable with SQL queries, perhaps an add-on to this data pipeline could be using AWS Quicksight for a more BI driven analysis.

Thanks for the read!
This story is authored by Santosh Kumar. He is an AWS Cloud Engineer.
Comments