
What is Elasticsearch and why should I know about it?
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search and analyze big volumes of data quickly and in near real time (Numbers, text, geo, structured, unstructured. All data types are welcome). It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements.
OK, so what can I do with it?
Well, you can develop a technology product using Elasticsearch, that can help in solving following use cases for –
- A Blogger – Are a lot of people talking about me on Facebook/Twitter/Linkedin? (Number of people who tagged/shared/mentioned me)
- A Budding Star – How popular Am I? Only my fans know me or the rest of the world as well?
- A Musician – I would like to hold a concert outside my country, how do I know where I’m popular?
- A Sales Manager – Are people talking about our product? Which social media platform is good for us ? Twitter? Facebook? Linkedin? (Breaking up and analyzing the data geography-wise in order to give a bird’s eye view of the scenario)
- A B2C manager – Once in a while, we end up with a customer who is unable to complete his order. We are forced to manually step in and complete his process. Is there a better way? (Analyzing and making sense of thousands of log files and pinpoint the cause of issue)
It is useful to look at some of the common terms in the world of Elasticsearch, and understand their definitions. If you would like, please look at the source here:
(https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html)
Cluster
A cluster is a collection of one or more nodes (servers) that holds together your entire data and provides federated indexing and search capabilities across all nodes. A cluster is identified by a unique name which by default is “elasticsearch” for an elasticsearch cluster. Grouping together of nodes (or servers or individual computers) helps in faster querying and load balancing.
Node
A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name which by default is a random Universally Unique Identifier (UUID) that is assigned to the node at startup.
Index
An index is a collection of documents that have somewhat similar characteristics. For example, you can have an index for customer data, another index for a product catalog, and yet another index for order data.
If you already have an idea of structured Databases, you can equate an Index to a Database.
Type
A type used to be a logical category/partition of your index to allow you to store different types of documents in the same index, eg one type for users, another type for blog posts. It is no longer possible to create multiple types in an index, and the whole concept of types has been removed in Elasticsearch 6.
A type stands equal to a table of a database.
Why are mapping types being removed?
(taken from official elasticsearch documentation https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html)
Initially, we spoke about an “index” being similar to a “database” in an SQL database, and a “type” being equivalent to a “table”.
This was a bad analogy that led to incorrect assumptions. In an SQL database, tables are independent of each other. The columns in one table have no bearing on columns with the same name in another table. This is not the case for fields in a mapping type.
In an Elasticsearch index, fields that have the same name in different mapping types are backed by the same Lucene field internally. In other words, using the example above, the user_name field in the user type is stored in exactly the same field as the user_name field in the tweet type, and both user_name fields must have the same mapping (definition) in both types.
On top of that, storing different entities that have few or no fields in common in the same index leads to sparse data and interferes with Lucene’s ability to compress documents efficiently.
For these reasons, the concept of mapping types from Elasticsearch has been removed.
Document
A document is a basic unit of information that can be indexed. For example, you can have a document for a single customer, another document for a single product, and yet another for a single order. This document is expressed in JSON (JavaScript Object Notation) which is a ubiquitous internet data interchange format.
A document stands equal to a row of a table.
Within an index/type, you can store as many documents as you want. Note that although a document physically resides in an index, a document actually must be indexed/assigned to a type inside an index.
Shards & Replicas
An index can potentially store a large amount of data that can exceed the hardware limits of a single node. And result in a node that may be too slow to serve search requests alone.
To solve this problem, Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent “index” that can be hosted on any node in the cluster.
The mechanics of how a shard is distributed and also how its documents are aggregated back into search requests are completely managed by Elasticsearch and is transparent to you as the user.
In a network/cloud environment where failures can be expected anytime, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index’s shards into what are called replica shards, or replicas for short.
How are Lucene and Elasticsearch connected?
Lucene or Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform. Elasticsearch is built over Lucene.
For now, this glossary of terms is good enough to get up and running with a basic setup of Elasticsearch.
Installing Elasticsearch on ubuntu
Official Debian package installation can be followed from
https://www.elastic.co/guide/en/elasticsearch/reference/current/deb.html
This page talks in detail about all the steps, configurations and issues.
If you wish to fast forward to a quick installation, you can follow the steps below (to install Elasticsearch on Ubuntu):
- Download and install the public signing key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
- Installing apt-transport-https will find the appropriate versions on the repositories.
sudo apt-get install apt-transport-https
- Save the repository definition to /etc/apt/sources.list.d/elastic-6.x.list
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
- Install Elasticsearch package
sudo apt-get update && sudo apt-get install elasticsearch
- To be able to access Elasticsearch from anywhere, make the following changes (not for production systems)
sudo vi /etc/elasticsearch/elasticsearch.yml
(this opens up the file in an editor to help us make changes)
Press the arrow keys to move down in the file and locate the following line
Network.host : 0.0.0.0 (this line is generally commented, uncomment it and update the host to all zeros as shown)
Press esc and then press :wq and enter. This will save the changes to the file and exit the file.
- To configure Elasticsearch to start automatically when the system boots up, run the following commands:
sudo /bin/systemctl daemon-reload sudo /bin/systemctl enable elasticsearch.service
- To start Elasticsearch
sudo systemctl start elasticsearch.service
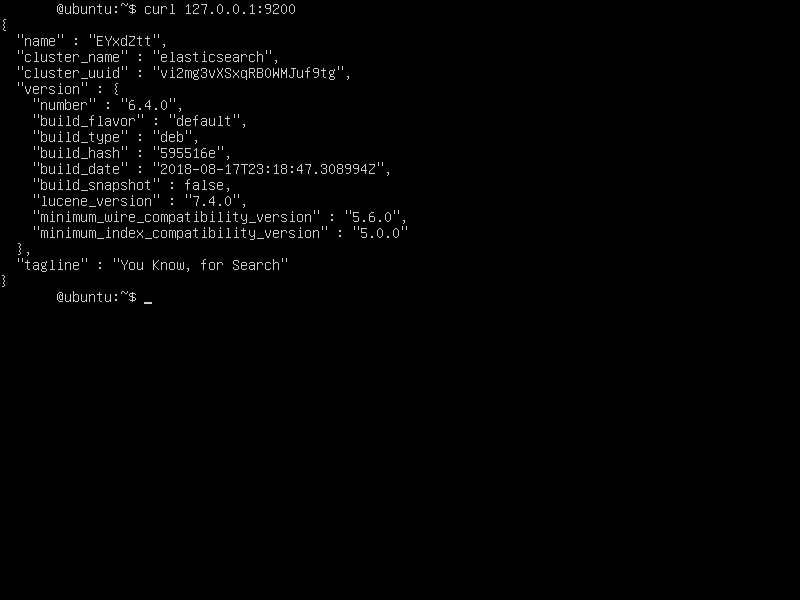
- Let’s test our Elasticsearch by typing
curl 127.0.0.1:9200
You will see something on similar lines.
Sample data sets are available on
https://www.elastic.co/guide/en/kibana/current/tutorial-load-dataset.html
Download the accounts json zip file (ready to use as it doesn’t require mapping) on the server using the command
wget https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
Unzip using
unzip accounts.zip
If Unzip is not available, download Unzip software using the command
sudo apt install unzip
(you might be asked for sudo password-enter and continue)

Once Unzip is successfully installed, you can run the above command and unzip the accounts.zip file. On successful completion, this creates the accounts.json file. We will use this file as our input, to enter data for our search queries.
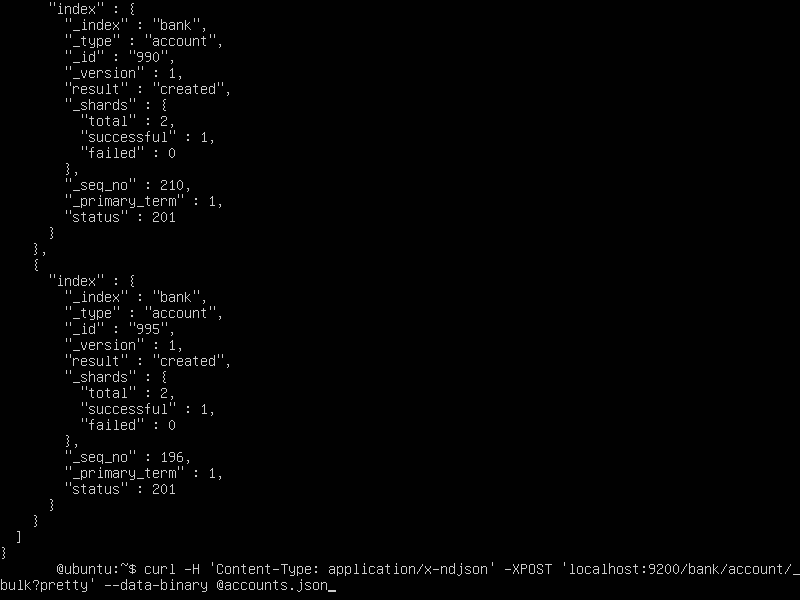
Run the following command to insert the json created above
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
(here, our index is ‘bank’ and our document is ‘account’)
Accessing our Elasticsearch from Python Client:
To install Elasticsearch package on Python, run the following command from terminal of Python installation
$pip install elasticsearch
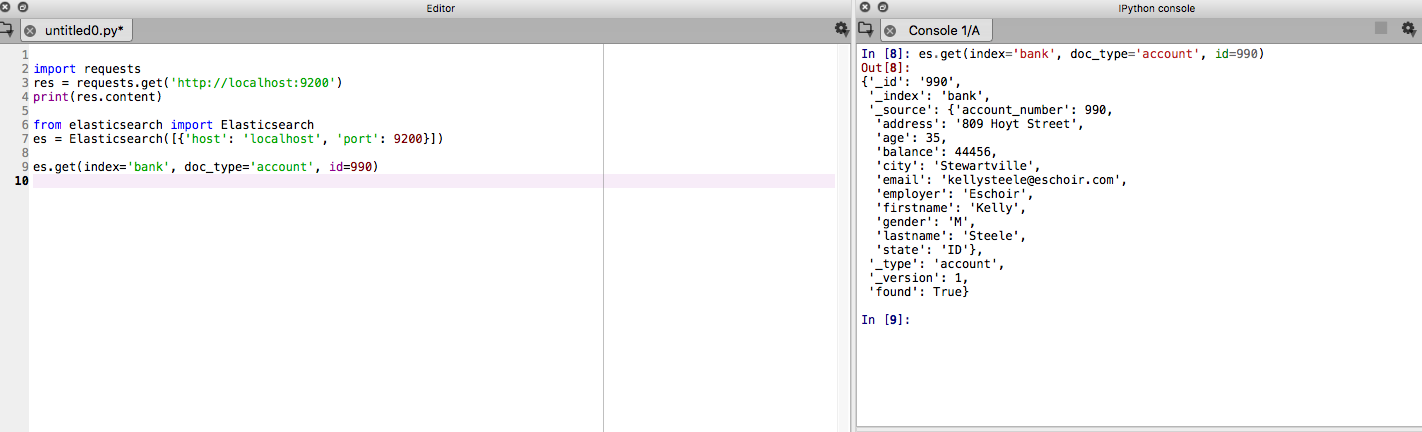
Let’s now look at a very simple python program to connect to our Elasticsearch engine and query for data.
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
es.get(index='bank', doc_type='account', id=990)
Output on the console will look like so : (data is retrieved from the accounts.json file that we had setup into our Elasticsearch cluster in the previous step).
Comments