Serverless Web Application Architecture using React with Amplify: Part1
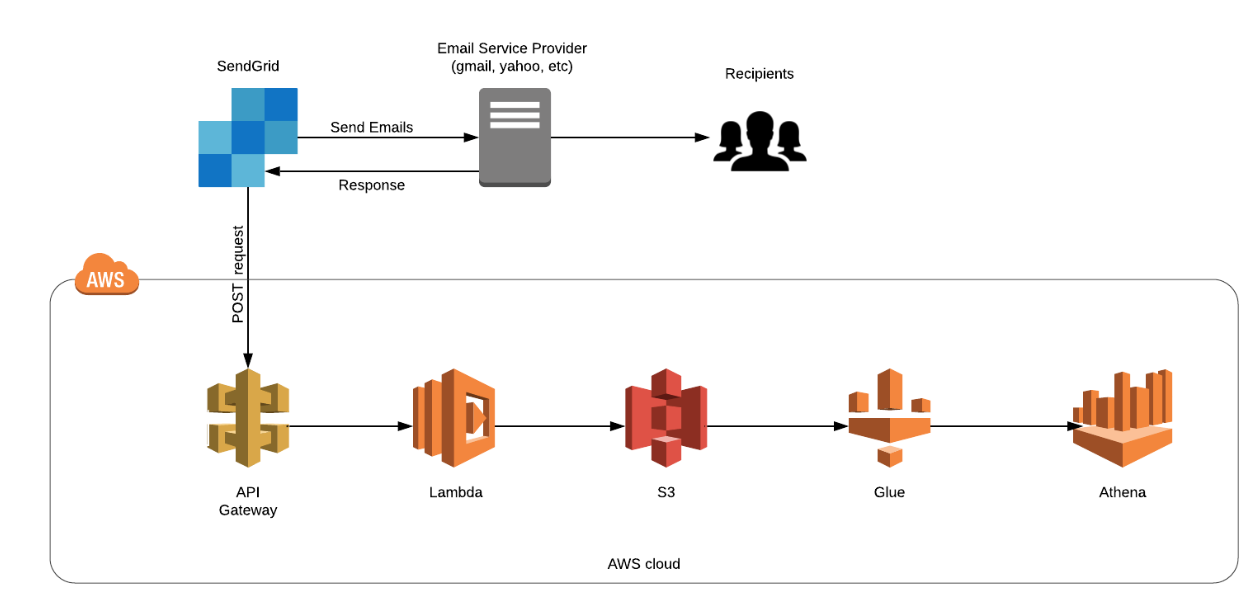
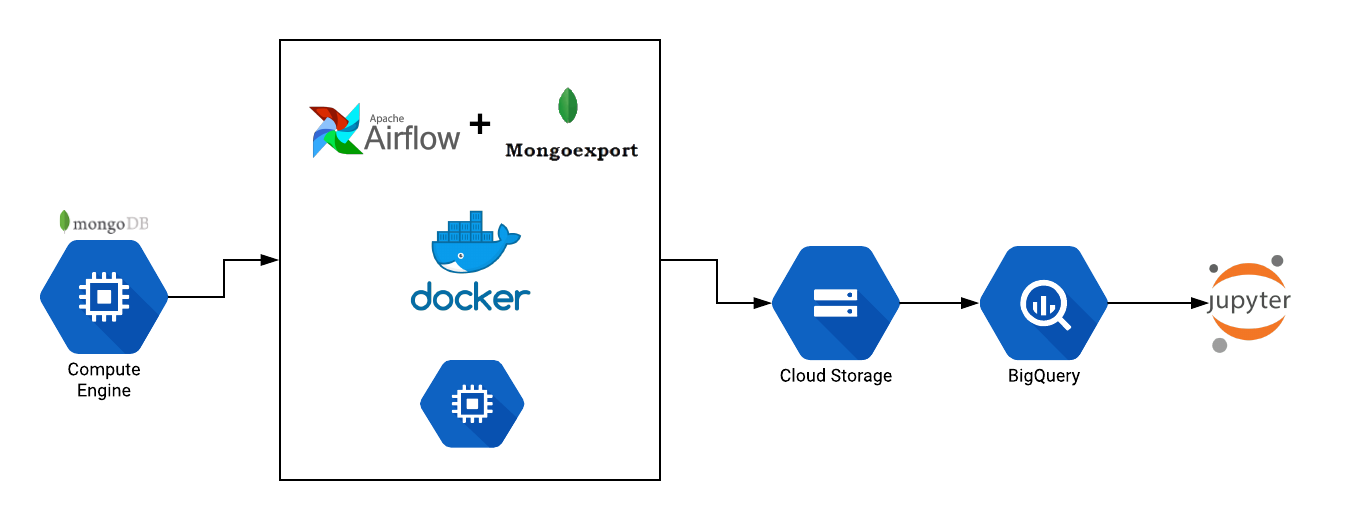
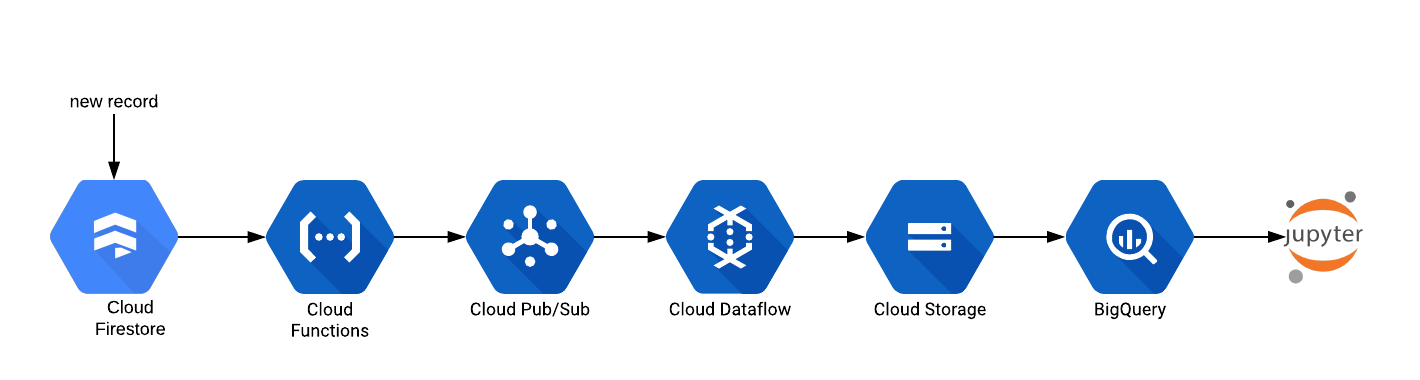
In this series we shall be building Jotter (a note taking app). Jotter is a serverless web application built with React and Amplify using AWS cloud services. The illustration below depicts the serverless architecture we are going to build. After deployment: Understanding Serverless: Just put your code on cloud and run it. Without worrying about... » read more